Dysphonia Severity Index (DSI) in Praat as a Tool for the Assessment of Singers of different Musical Styles: Classical and Flamenco
*Corresponding Author(s):
Marina GarzónExperimental And Applied Speech Terapy Research Group (HUM605), Granada University. Estudio De Voz Marina Garzón, Spain
Email:estudiodevozmarinagarzon@gmail.com
Abstract
Purpose: The aim of this study is to compare the DSI calculated from Multi-Dimensional Voice Program (KayPENTAX Corp., Montvale, NJ) and the DSI beta, implemented in the program Praat in singers of different musical styles; Western classical and
Method: the sample was formed by 34 professional or aspiring professional singers; 16 Flamenco singers (FG) and 18 Western Classical singers (CG). Measures of Maximum Phonation Time, Highest Fundamental Frequency, Lowest Intensity and pitch perturbation were obtained for each index. T-Test was run for all the study’s variables between groups and sex. From the DSI and DSI beta values, the Pearson correlation coefficient was extracted.
Results: scores were very high with respect to normal healthy subjects. DSI beta (men=4.52; women=5.73) showed concurrent validity with DSI (men=5.72; women=7.44) when applied in singers (rp=0.869) and greater variability among CG than FG, compared to DSI original. F0.hi was higher in the CG, Jitt% showed more variability in the FG and jitter ppq% was not sensitive to musical style. Intensity values were around 40db for both groups and indices. Maximum Phonation Time was not exceptionally high.
Conclusion: DSI original is capable of distinguishing between flamenco and classical, while DSI beta is not. This capability is due to the effect of the perturbation parameters that varied more among flamenco singers than among classical singers.
Keywords
Dysphonia severity index; Flamenco; Praat; Singer; Voice quality
Introduction
The assessment of high-performance voices requires the analysis of vocal quality, a phenomenon that results from the interaction of different vocal mechanisms. Vocal quality is fundamentally perceptual in nature and analysis based on listeners’ judgment is often used to evaluate it [1]. But auditory-perceptual analysis has multiple limitations; problems with scale validity and reliability, particularly for mild to moderate pathological voices; poorly defined and/or shifting definitions of severity; and the intrusive effects of voice and speech characteristics other than the quality dimension that is meant to be judged [2] and it is not sufficiently refined for the evaluation of singing voices [3] although there are some exceptions in classical singing [4].
Acoustic voice analysis is the most frequently studied domain in voice literature [5] and it has demonstrated greater sensitivity than auditory-perceptual analysis in discriminating subtle changes in the singing voice [6]. One tool capable of measuring the multidimensional elements of the voice is the Dysphonia Severity Index (DSI), proposed by Wuyts [7] DSI uses a combination of acoustic and aerodynamic measures: highest fundamental frequency (F0.hi), lowest intensity (I.low), maximum phonation time (MPT) and pitch perturbation (Jitter %).
The Index was created by correlating the results of a study involving 387 subjects using acoustic, aerodynamic and self-reporting measurements and also auditory-perceptual assessment methods, such as the GRBAS perceptual assessment scale [8]. Subsequent studies have confirmed the validity of the DSI levels [9]. The DSI is a continuous measure with two anchor points: +5 corresponds to a perceptually normal voice and –5 corresponds to a severely dysphonic voice, although any score of +1.6 and higher is considered a normal voice. DSI has been used mainly as a measure of the degree of vocal dysphonia because it differentiates between healthy voices and pathological voices [10]. DSI has been used in the evaluation of the vocal quality of singers in numerous studies. A study by [11] measured vocal improvement in students who received training in relaxation, posture, breathing patterns and articulation, and found an increase of 2.3 to 4.5 points after instruction; compared singers with and without vocal training, finding different scores for each group (+6.48 and +4.00 respectively), with the differences being attributed to higher F0.hi values and higher MPT in the trained group. Studied 45 carnatic singer were with voice problems were analyzed [12]. The DSI findings were − 3.5 to 4.91, indicative of severe deviation to normal quality of voice. The researchers found the DSI is able to differentiate between singers and non-singers [13].
However, alternative normative expectations may need to be considered when using DSI with singers. There are not enough studies to establish specific normative data as regards the DSI for singers, as reviews conducted to date do not consider populations of singers [14]. Normative data is also lacking because of the impossibility of generating studies with easily accessible tools; it has been possible to obtain the Index only through expensive software used exclusively at research laboratories and certain universities. In consequence, [15] designed a version of the DSI for the Praat program which they called DSI beta. Praat is a freely available software package for formatting and analysing sound signals; it is easily accessible and simple to use in clinics and schools.
The aim of the present study is a) to expand the DSI sample, both the original version and the beta version, so as to include singers of musical styles as different as Western classical and flamenco and b) to evaluate the effect of style on the acoustic and aerodynamic measures of each index (DSI beta and original version).
Method
Participants
The study sample consisted of 34 singers (15 men and 19 women) recruited from the following institutions: Fundación Cristina Heeren Sevilla instead of Seville Superior de Música Victoria Eugenia (Granada) and Conservatorio Superior de Música (Málaga). Excluded from the sample were singers who reported surgery or medical treatment for any kind of vocal or respiratory pathology within the last three years. The participants attended regular classes every week in which they practiced the repertoire typical of each musical style, flamenco or Western classical. They all sang professionally or hoped to do so in the future. The sample of singers was divided into a) Flamenco Group, FG (n16) and b) Classical Group, CG (n18) Table 1.
|
|
FG |
CG |
|
Female |
9 |
10 |
|
Male |
7 |
8 |
|
Total |
16 |
18 |
|
|
34 |
|
|
Age |
36(17.6) |
33 (10.7) |
|
Career (years) |
9.75 |
4.97 |
Table 1: Sample distribution of Flamenco Group (FG) and Classical Group (CG) according to gender, age and years of career.
Tasks
Each participant was asked to complete a brief questionnaire that included demographic information, experience and singing practice habits, plus a short clinical history. Then the parameters were collected:
- The subject was instructed to make the sound /a/ at a comfortable pitch and intensity for at least 5 seconds. Three trials were performed The sound selected for analysis was extracted from the highest quality sustained vowel from the middle part of the recording.
- A trained experimenter presented the pitch (C4) on a digital keyboard, following the procedure proposed by [16]. The subject was asked to imitate it at a comfortable volume and then gradually reduce the volume until reaching the lowest possible volume without breaks or whispering for at least 2 seconds.
- The subject was asked to sing the vowel /o/ at a comfortable intensity and pitch. The experimenter, using a digital keyboard, then played, semitone by semitone, an ascending scale and instructed the singer to follow, starting with the comfortable pitch chosen up to the highest pitch that the singer could produce, without loss of control or voice breaks, for at least 2 seconds. This procedure was followed three times and the highest frequency attained was noted.
- The Maximum Phonation Time (MPT) was measured by instructing the subject to sing, after a deep inhalation, the vowel /a/ at a comfortable tone and intensity for the longest time possible. This task was performed three times and the best time was chosen.
Recordings, DSI calculation and statistical analysis
DSI original = 0.133 x MPT + 0.0053 x F0high – 0.263xIlow -1.183 x Jitt + 12.4
DSI beta = 1.127+ 0.164 × MPT + 0.0053 × F0high – 0.038 x Imin- 5.30 x Jitterppq
For the statistical analysis, first a T-test was run to check for equality of means, modifying the degrees of freedom when the data failed Levene’s test for equality of variances. Then, from the values obtained from the two indices, original and beta, the Pearson correlation coefficient was extracted.
Results
Below the descriptive statistics are presented, by sex and experimental group, for all the study’s variables (Table 2), along with results of Levene's test for equality of variances and of the T-test for equality of means between groups (Table 3) and between sexes (Table 4), having modified the degrees of freedom when Levene's assumption of equality of variances was not met with a confidence interval of 95%.
|
|
FG |
CG |
total |
|||
|
|
H |
M |
H |
M |
H |
M |
|
F0hig. (hz) |
399.29(38.65) |
485.69(37.1) |
382.09(64.09) |
936.69(142.65) |
390.11 |
723.06 |
|
447.89 (57.36) |
690.2(304.75) |
|||||
|
Ilow (db) |
41.02(5.17) |
43.48(4.07) |
43.10(4.06) |
37.76(5.75) |
42.13 |
40.47 |
|
42.4(4.59) |
40.13(5.63) |
|||||
|
Jitt% |
0.97(0.97) |
0.5(0.52) |
0.32(0.18) |
0.57(0.45) |
0.62 |
0.54 |
|
0.71(0.76) |
0.46(0.37) |
|||||
|
MPT (s) |
25.36(8.47) |
20.01(4.32) |
21.15(6.92) |
17.69(5.34) |
23.12 |
18.79 |
|
22.34(6.79) |
19.22(6.15) |
|||||
|
DSI original |
5.95(2.55) |
5.61(1.22) |
5.53(1.93) |
9.11(2.04) |
5.72 |
7.44 |
|
5.81(1.82) |
7.58(2.64) |
|||||
|
Imin (db) |
41.11(5.32) |
43.61(4.26) |
42.9(4.02) |
37.75(5.62) |
42.13 |
40.06 |
|
42.52(4.76) |
40.04(5.51) |
|||||
|
Jitterppq5% |
0.19(0.12) |
0.14(0.08) |
0.14(0.05) |
0.15(0.07) |
0.16 |
0.14 |
|
0.16(0.1) |
0.14(0.06) |
|||||
|
DSI beta |
4.83(1.43) |
4.58(0.74) |
4.26(1.57) |
6.77(1.48) |
4.52 |
5.73 |
|
4.69(1.06) |
5.66(1.96) |
|||||
Table 2: Descriptive statistics on original DSI and its parameters on FG and CG.
First of all, significant between-group differences can be observed in the variance of F0.hi, with higher values in the CG (t=-3.126; p<0.001); in that of Jitt%, where the FG showed more variability in its scores (t=-1.183; p<0.05) and also in that of DSI beta, where the CG had the most variable scores (t= -1.821; p>0.05).
Comparing the sexes, significant differences in variance in F0.hi (t= 5.573; p>0.001) are observed only in the group of women, as expected. In addition, when comparing the means of the groups, DSI original in FG scores 5.81 while in CG scores 7.58. FG obtained significantly lower values in F0.hi and in DSI original (t= -2.282; p>0.001) with respect to the CG. In the other variables no statistically significant differences are observed between the groups. For the analysis of the sexes in the sample, significant differences are found between the means of F0.hi (p>0.001) and also in the DSI original (t= 2.149; p>0.05), the differences being greater in women than in men.
|
|
|
|
T-test
|
|
|
|
Levene
|
t |
Sig. (bilateral) |
|
|
|
F |
Sig. |
|
|
|
Fo.hi |
57.44 |
.000** |
-3.308 |
.004* |
|
I.low |
0.139 |
0.712 |
1.277 |
0.211 |
|
Jitt% |
7.67 |
.009* |
1.183 |
0.25 |
|
MPT |
0.208 |
0.652 |
1.404 |
0.17 |
|
DSI original |
3.051 |
0.09 |
-2.211 |
.034* |
|
I.mín |
0.39 |
0.845 |
1.396 |
0.172 |
|
Jitterppq% |
3.256 |
0.081 |
0.666 |
0.512 |
|
DSI beta |
7.026 |
.012* |
-1.821 |
0.08 |
|
*p≥0.05/**p>0.01 |
|
|
|
|
Table 3: Levene and T-test results for original DSI and its parameters and DSI beta and its parameters, in FG and CG.
|
|
|
|
T-Test |
|
|
|
Levene |
T |
Sig. (bilateral) |
|
|
|
F |
Sig. |
|
|
|
Fo.hi |
45.443 |
.000** |
5.573 |
.000** |
|
I.low |
1.9 |
0.178 |
-0.918 |
0.366 |
|
Jitt% |
2.143 |
0.153 |
-0.41 |
0.684 |
|
MPT |
3.045 |
0.091 |
-1.995 |
0.055 |
|
DSI original |
0.697 |
0.41 |
2.149 |
.039* |
|
I.mín |
2.276 |
0.141 |
-0.847 |
0.403 |
|
Jitterppq% |
0.439 |
0.513 |
-0.645 |
0.523 |
|
DSI beta |
0.198 |
0.659 |
2.249 |
.032* |
|
*p≥0.05/**p>0.01 |
|
|
|
|
Table 4: Levene and T-test results for original DSI and its parameters and DSI beta and its parameters studied in men and women.
Last of all, there is a significantly high and positive linear correlation between DSI original and DSI beta scores (rp=0.869; p>0.01), as illustrated in the following dispersion graph (Figure 1). DSI beta variance represents 75.5% of DSI original variance, due to the coefficient of determination obtained (rp2=0.755).
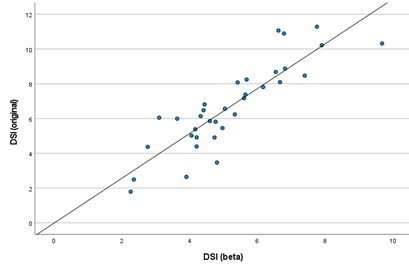 Figure 1: Scatterplot illustrating the proportional relationship between the DSI original and the DSI beta (n=34). The linear regression line corresponds with rp2=0.755
Figure 1: Scatterplot illustrating the proportional relationship between the DSI original and the DSI beta (n=34). The linear regression line corresponds with rp2=0.755
Discussion
The Dysphonia Severity Index is a sensitive and objective measure for analyzing vocal quality. The 34 singers participating in this study were found to have a DSI of 5.72 in the case of men and 7.44 in the case of women. As in 3.8 in women [9]. In a recent review of 1330 studies [14] it was established that the normative mean of healthy voices is 3.05 with a confidence level of between 2.13 and 3.98. Past studies have shown that DSI original can differentiate between trained voices (≈6.5) and untrained voices (4.00) [2,11]. Specific vocal training results in a significant increase in Authors conclude that this effect is due to such vocal training increasing both frequency and dynamic range. It may be, however, that the differences between the groups is not explained just by the training effect, since in previous studies the flamenco singers did not carry out specific vocal training sessions, while the classical singers did [20]. The results of the present study are - consistent with other studies although associate a higher DSI score with specific singing training. The differences in DSI found between the groups could be attributed to the influence of the musical style, of the training received and of practice per se. Taining and regular in activities involving singing improve DSI scores. As for the comparison of index scores, DSI beta has shown a sufficiently high concurrent validity with DSI original when applied in singers (rp=0.869), as was also found in subjects with vocal pathologies (rp=0.851), [15]. The authors assume that this result is acceptable but incomplete and that it is due to the effect of the frequency parameter on the protocol. For this reason, and because F0high is an especially sensitive parameter in singers, it was decided that the protocol proposed would be used to obtain the DSI in singers, so as to rule out the possible contaminating effect of this parameter. In this protocol the evaluator must have a trained ear, an essential condition in the evaluation of singing voices. Nonetheless, DSI beta showed greater variability among classical singers than among flamenco singers, compared to DSI original. Furthermore, DSI beta is not capable of distinguishing between musical styles while DSI original is.
As for variability, it may be due to several different factors. On the one hand, the frequency parameter is more variable among classical singers than among flamenco singers. Finding differences in F0hi within the groups could be expected, because men have a lower register than women. However, such variability is not observed in the flamenco singers. In flamenco singing women use the contralto or mezzo soprano range, while trying to make their singing voice sound like the spoken voice. In other words, they naturalize it. Naturalizing the sound requires avoiding certain technical licenses associated with classical singing that sacrifice the intelligibility of vowels in order to reach higher notes [21]. In addition, as regards the effect of the perturbation parameters, jitt% varied more among flamenco singers than among classical singers while jitterppq% was not sensitive to this variable. It would be interesting to explore the direction and effect these parameters have on DSI beta and not on DSI original.
As mentioned above DSI original is capable of distinguishing between flamenco and classical, while DSI beta is not. It is reasonable to suppose that this capability is due to the effect of the perturbation parameters and not to the frequency parameters, which were the same for both indices. In previous studies the perturbation of the signal has been used to distinguish between musical styles. Specifically, [22] differentiated between musical styles such as country, opera, jazz, musical theatre, soul and pop and they found that perturbation rates in opera singers, with a jitter of 0.52, were significantly higher than in singers specialized in other musical styles. The classical singers of the present study had a jitter of 0.46 (the group includes classical singers in general, not just opera singers) while the flamenco singers had a jitter of 0.71. This parameter depends on biomechanical, neurological and aerodynamic factors. More in-depth studies on the perturbation parameter in singers are needed to better explain the precise implications of this finding.
In relation to the minimum phonation intensity, values around 40db were obtained, while in normal subjects the value is approximately 56db. We can thus conclude that in singers this parameter is lower than in the normal population. Our findings concur with the literature. For example, Awan y Ensslen [11] the strengthening of abdominal muscles and the diaphragm, while Sulter, [23] attribute them to the training of the respiratory apparatus and the thickening of the vocal folds. Flamenco singers do not attend vocal technique classes nor do they train their voices in a particular manner or do warm-up exercises and yet they obtain the same I. low as classical singers. Flamenco singers tend to sing for a much longer time than classical singers. Practice habits and musical style could be affecting this parameter in singers. Despite suggestions in some papers about the increase in breathe control among singers. [24] We found no exceptionally high MPT scores in our sample and the means of the groups were very similar to normative values of subjects with healthy voices. we did, however, find a greater duration among flamenco singers than among classical singers, although the difference was not significant. [25] found that MPT actually decreased after a session of vocal training. They speculated that this effect on phonation time could be due to greater glottic resistance and more relaxed vocal folds in singers than in non-singers. Efficient use of the physiological vocal system entails balancing air, laryngeal muscle activity and supraglottic placement of pitches [26].
Conclusion
Its sensitivity to the effect of training, along with its capacity for quantifying it, has made DSI a much used index in research into the singing voice. Yet the application of DSI in the fields of pedagogy and clinical evaluation remains scant because of the lack of essential technical resources. Another drawback of the DSI is that some of its parameters can produce false positives, indicating the presence of pathology when there is none, and these parameters must be interpreted very carefully in the case of the singing voice. In addition, the values obtained from such parameters vary among the different musical styles. Future research should try to develop a normative DSI base, especially considering the current search for new F0.hi and I.low values for singers, since these values change as a result of vocal training, with respect to the average population. Also, the frequency and perturbation parameters must be treated with special consideration in relation to the distinction between musical styles.
DSI beta has shown sufficiently high concurrent validity with DSI original in its application in singers, but it must be further refined because a shadowing effect generated by the perturbation parameter has been found. The further development of DSI beta could facilitate the increase of normative data that would allow comparisons in subgroups of singers.
Acknowledgment
The authors of this study would like to thank Fundación Cristina Heeren de Arte Flamenco and Conservatorio Cristóbal de Morales from Seville, Escuela Municipal de Flamenco Reina Sofía and Conservatorio Superior de Música Victoria Eugenia from Granada and also Conservatorio Superior de Música (Málaga) without whom this research could not take place. The willing help of the participants is also gratefully acknowledged. Finally a warm thanks Elvira Mendoza for her helpful advices.
References
- Kreiman J, Gerratt BR, Kempster G, Erman A, Berke GS, et al. (1994) Perceptual evaluation of voice quality: review, tutorial, and a framework for future research. Journal Speech Hear Research 36: 21-40.
- Awan S, Ensslen A (2010) A Comparison of Trained and Untrained Vocalists on the Dysphonia Severity Index. Journal of Voice 24: 661-666.
- Sundberg J (2003) Research on the singing voice in retrospect. TMH-QPSR 45: 11-22.
- Oates JM, Bain B, Davis P, Chapman J, Kenny D, et al. (2006) Development of an auditory-perceptual rating instrument for the operatic singing voice. Journal of Voice 20: 71-81.
- Roy N, Barkmeier-Kraemer J, Eadie T, Sivasankar MP, Mehta D, et al. (2013) Evidence-based clinical voice assessment: A systematic review. Am J Speech Lang Pathol 22: 212-226.
- Gunjawate DR, Ravi R, Bellur R (2018) Acoustic analysis of voice in singers: a systematic review. J Speech Lang Hear Res 61: 40-51.
- Wuyts F, De Bodt M, Molenberghs G (2000) The Dysphonia Severity Index: an objective measure of vocal quality based on a multiparameter approach. J Speech Lang Hear Res 43: 796-809.
- Hirano M (1981) Clinical Examination of Voice. New York: Springer-Verlag.
- Hakkesteegt MM, Brocaar MP, Wieringa MH, Feenstra L (2008) The relationship between perceptual evaluation and objective multiparametric evaluation of dysphonia severity. Journal of Voice 22: 138-145.
- Nemr K, Simoes-Zenari M, De Souza G, Hachiya A, Tsuji D, et al. (2015) Correlation of the Dysphonia Severity Index (DSI), Consensus Auditory-Perceptual Evaluation of Voice (CAPE-V), and gender in Brazilians with and without voice disorders. J Voice 30: 765.e7-765.e11.
- Timmermans B, De Bodt M, Wuyts F, Heyning PHVD (2005) Analysis and evaluation of a voice-training program in future professional voice users. Journal of Voice 19: 202-210.
- Arunachalam R, Boominathan P, Mahalingam S (2014) Clinical voice analysis of Carnatic singers. Journal of Voice 28: 128-e1.
- Maruthy S, Ravibabu P (2015) Comparison of dysphonia severity index between younger and older carnatic classical singers and nonsingers. J Voice 29: 65-70.
- Soboln M, Sielska-Badurek EM (2020) The Dysphonia Severity Index (DSI)-Normative Values. Systematic Review and Meta-Analysis. Journal of Voice
- Maryn Y, Morsomme D, De Bodt M (2017) Measuring the Dysphonia Severity Index (DSI) in the program praat. Journal of Voice 31: 644-e29.
- Ma E, Robertson J, Radford C, Vagne S, El-Halabi R, et al. (2007) Reliability of speaking and maximum voice range measures in screening for dysphonia. Journal of Voice 21: 397-406.
- Boersma P (2001) Praat, a system for doing phonetics by computer. Glot International 5: 341-345.
- Zraick RI, Nelson JL, Montague JC, Monoson PK (2000) The effect of task on determination of maximum phonational frequency range. Journal of Voice 14: 154-160.
- Barrett EA, Lam W, Yiu EM (2020) Elicitation of minimum and maximum fundamental frequency and vocal intensity: Discrete half steps versus glissando. Journal of Voice 34: 179-196.
- Garzon M, Munoz J (2017) Voice habits and behaviors: voice care among flamenco singers. Journal of Voice 31: 246-e11.
- Garzon M, Munoz J (2018) The resonance of flamenco singing: an acoustic and comparative study with classical singing. Journal of Logopedia, Phoniatrics and Audiology 38:168-173.
- Butte CJ, Zhang Y, Song H, Jiang JJ (2009) Perturbation and nonlinear dynamic analysis of different singing styles. Journal of Voice 23: 647-652.
- Sulter A, Schutte H, Miller D (1995) Differences in phonetogram features between male and female subjects with and without vocal training. Journal of Voice 9: 363-377.
- Watson PJ, Hixon T (1985) Respiratory kinematics in classical (opera) singers. Journal Speech Hear Res 28: 104-122.
- Sulter AM, Meijer JM (1996) Effects of voice training on phonetograms and maximum phonation times in female speech therapy students. Variation of voice quality features and aspects of voice training in males and females
- Stager SV, Bielamowicz SA, Regnell JR, Gupta A, Barkmeier JM, et al. (2000) Supraglottic activity: evidence of vocal hyperfunction or laryngeal articulation?. J Speech Lang Hear Res 43: 229-238.
Citation: Garzón M and Muñoz J (2021) Dysphonia Severity Index (DSI) in Praat as a Tool for the Assessment of Singers of different Musical Styles: Classical and Flamenco. J Otolaryng Head Neck Surg 7: 58
Copyright: © 2021 Marina Garzón, et al. This is an open-access article distributed under the terms of the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original author and source are credited.