Hotspot Detection in Traditional Chinese Medicine Based on PubMed
*Corresponding Author(s):
Guo-Zheng LiDepartment Of Control Science And Engineering, 4800 Cao’an Road, China Academy Of Chinese Medical Science, Beijing 100700, Tongji University, Shanghai 201804, China
Tel:+86 1064089668,
Email:gzli@ndctcm.cn
Abstract
Objective: As the development of Traditional Chinese medicine (TCM), more and more researchers engage in the study of TCM. Meanwhile, some aspects of TCM are paid more attention by TCM researchers, which are regarded as specific hotspot research directions on the field of TCM. These hotspot research directions can help the researchers understand the dynamic change of TCM researches and guide their future research plan. Therefore, it is meaningful to mine hotspots of TCM from the existing database.
Methods: Based on the E-utilities interface of PubMed, the source data can be obtained. They are 10291 abstracts on TCM including manually annotated MeSH terms. Moreover, two hotspot detection schemes are developed according to the characteristics of the source data, one is based on Medical Subject Headings (MeSH) terms co-occurrence while the other is based on text network.
Results: From the experiments results on different hotspot detection schemes, similar key words are obtained to describe major research directions of TCM. Then, according to domain knowledge and practical experience of TCM experts, four consistent hotspots are derived with two different hotspot detection schemes. As shown in the followings: (1) Research on Chinese medical formula and its mechanism of action, (2) Research on pharmacology and pharmacodynamics of antineoplastic agent in TCM, (3) Research on the therapy of chronic diseases in TCM, and (4) Research on traditional therapy methods in TCM.
Conclusion: We study the hotspots detection and dynamic change for TCM research directions on PubMed. The experimental results validate the effectiveness of the proposed approach. Although the proposed schemes are applied to TCM in our research, they also can be extended to other academic fields.
Keywords
INTRODUCTION
As data resource on TCM is countless, it is not feasible to deal with these data just rely on expert statistics. Researchers develop several methods to detect hotspots in different fields such as mapping [1-3], clustering [4-6] and visualization [7,8]. Clustering is a popular technology always used in text mining domain. He et al., [9] recognize hot events with TF-IDF model and incremental cluster algorithm. Li et al., [10] adopt SVM and K-means to cluster texts and take the centers of clusters as the hotspots. In addition, various measures are applied such as term frequency analysis, citation analysis and co-occurrence of keywords or authors. Haribhakta et al., [11] represent documents with keywords and compare the co-occurrence of keywords to detect hot topic. Bu-Yeo Kim et al., [12] compare the co-occurrence of keywords to map the dementia research area at the micro-level. All these works focus on hot topic detection with singular scheme, such as the straightforward keywords statistics. However, it is hard to validate the detection confidence due to lack of quantitative ground truth assessment with singular scheme. Therefore, we propose two different schemes for different data subjects, which could mutually validate the hotspots detection results to each other. For specific application, we apply them into TCM domain to mine the research directions in certain years. Moreover, the research hotspots transfer issues of TCM are also studied through the proposed approaches.
This paper is organized as follows: we first introduce the flowchart of our hotspots detection schemes step by step. Then, articles of PubMed database on the field of TCM researches are taken as an instance to perform our experiment. Furthermore, we analyze the hotspots detection results and discuss the advantages and disadvantages of our approaches. Finally, we make a conclusion of our work.
MATERIALS AND METHODS

Data collection and preprocessing
Feature set selection and similarity computation
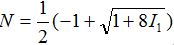
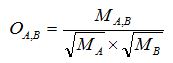
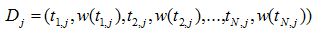
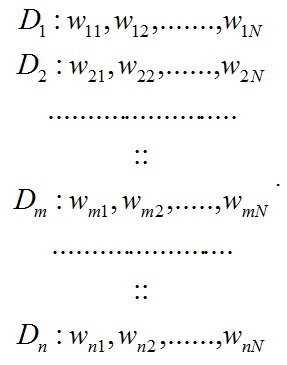
MeSH terms/text clustering and hotspots detection
In the first scheme, a classical clustering algorithm k-means is utilized to group similar MeSH terms. MeSH terms are clustered into different categories, which are regarded as hotspot key words information. Then final highly summarized hotspots are concluded by experienced experts in detail.
Similarly in the second scheme, we adopt spectral clustering algorithm to group similar articles into same categories. According to clustering results, the MeSH terms of each article are taken as keywords, all high-frequency keywords are extracted for experts to make final hotspots deduced.
RESULTS
Results based on MeSH terms co-occurrence
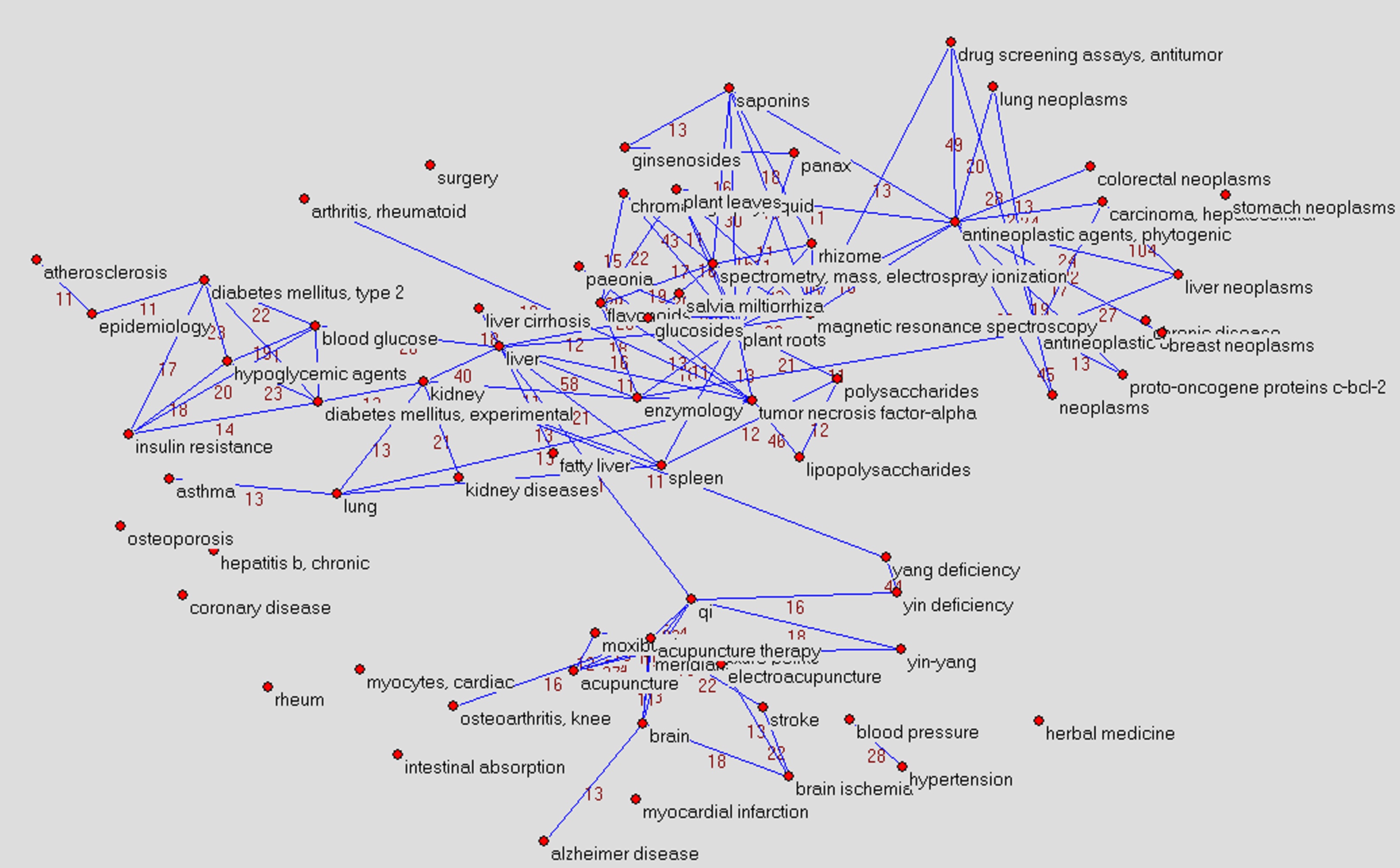
In figure 2, the blue line values represent the frequency of two related terms appearing in the same article. Seen from the visual relationships of terms, we can easily divide the terms into four parts, circled with four different colors. Terms in the same part are similar with each other, and can reflect hot topics. This is also a considerable method to discovery hot topics. But this method is subjective and coarse which might not accurately reflect the research hotspots. Thus, it is more feasible to apply this network to calculate the similarities of all extracted terms appearing in the same article. Then, the k-means clustering algorithm can be performed to divide the data into 10 clusters. Final hotspots deduction is carried out by TCM experts.
Here, we list the first four primary hotspots discovered by our approach. The terms in parentheses are key words which can reflect the hotspots information as shown in figure 3.
- Research on Chinese medical formula and its mechanism of action. (plants, medicinal; technology, pharmaceutical; seeds; fruit; rhizome; plant leaves; alkaloids; lignans; plant stems; saponins).
- Research on traditional therapy methods in TCM (mainly acupuncture).(acupuncture; acupuncture therapy; moxibustion; electroacupuncture; stroke; acupuncture points; meridians).
- Research on pharmacology and pharmacodynamics of antineoplastic agent in TCM. (antineoplastic agents; antineoplastic agents, phytogenic; drug screening assays, antitumor; neoplasms; liver neoplasms; carcinoma, hepatocellular; gene expression regulation, neoplastic; xenograft model antitumor assays; lung neoplasms).
- Research on the therapy of chronic diseases in TCM (mainly diabetes). (hypoglycemic agents; body weight; diabetes mellitus, type 2; blood glucose; diabetes mellitus, experimental; hypertension; brain ischemia; myocardium; blood pressure).

RESULTS BASED ON TEXT NETWORK
- Research on Chinese medical formula and its mechanism of action. (plant extracts; cordyceps; plants, medicinal; rhizome; coptis; salvia miltiorrhiza; ginsenosides; reishi)
- Research on pharmacology and pharmacodynamics of antineoplastic agent in TCM. (antineoplastic agents; antineoplastic agents, phytogenic; cell line, tumor; apoptosis; gene expression regulation, neoplastic; carcinoma, hepatocellular; liver neoplasms; breast neoplasms; neoplasm invasiveness; lung neoplasms; carcinoma, non-small-cell lung; drug screening assays, antitumor; stomach neoplasms; tumor necrosis factor-alpha; neoplasm transplantation)
- Research on the therapy of chronic diseases in TCM (mainly diabetes). (kidney diseases; kidney; kidney failure, chronic; parkinson disease; blood; blood glucose; insulin resistance; liver cirrhosis, experimental; liver cirrhosis; alzheimer disease; cognition disorders; atherosclerosis; coronary disease; hepatitis b virus; hepatitis b, chronic; pulmonary disease, chronic obstructive; arthritis, rheumatoid; osteoporosis; diabetes mellitus, type 2; diabetes mellitus, experimental; insulin)
- Research on traditional therapy methods in TCM (mainly acupuncture).(acupuncture therapy; acupuncture points; meridians; pain measurement; pain management; acupuncture; electroacupuncture; moxibustion)
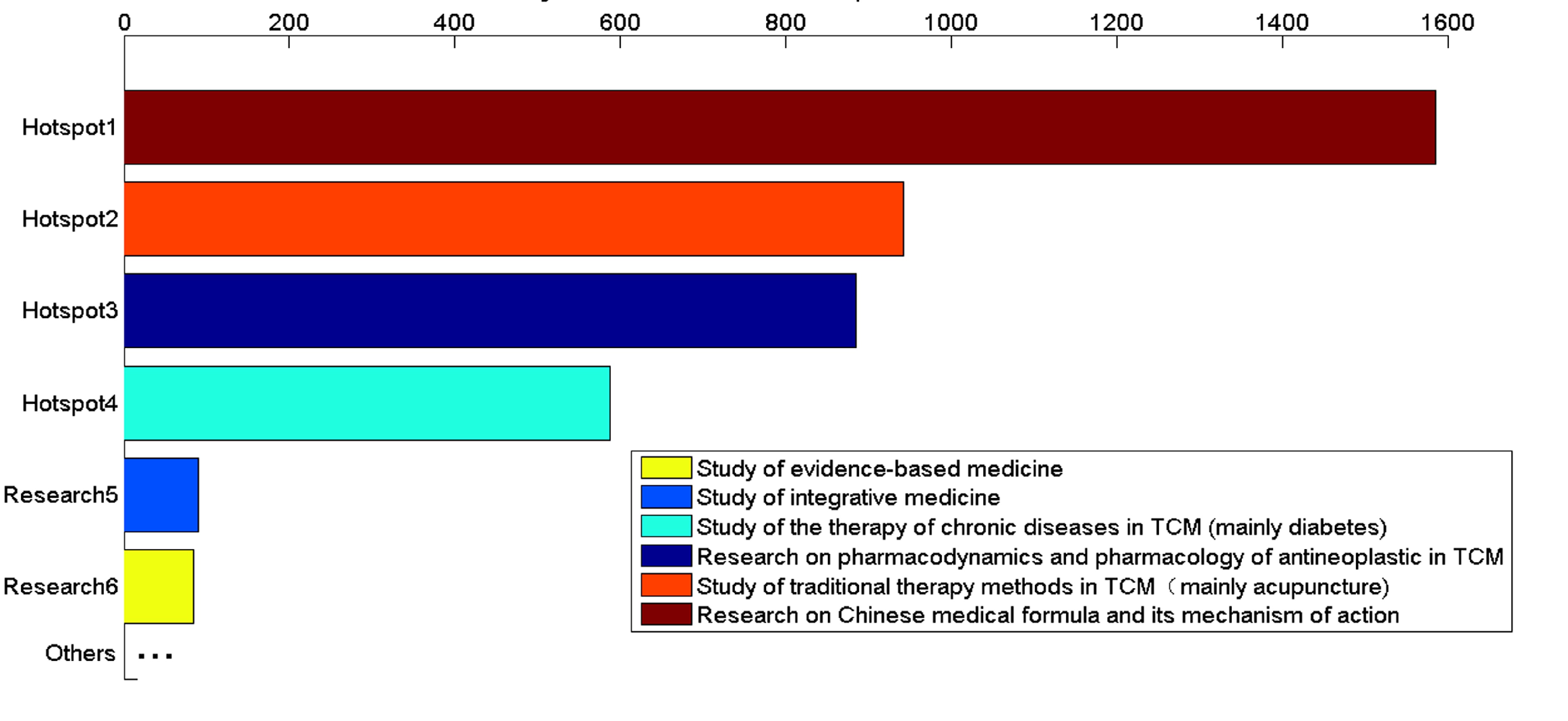
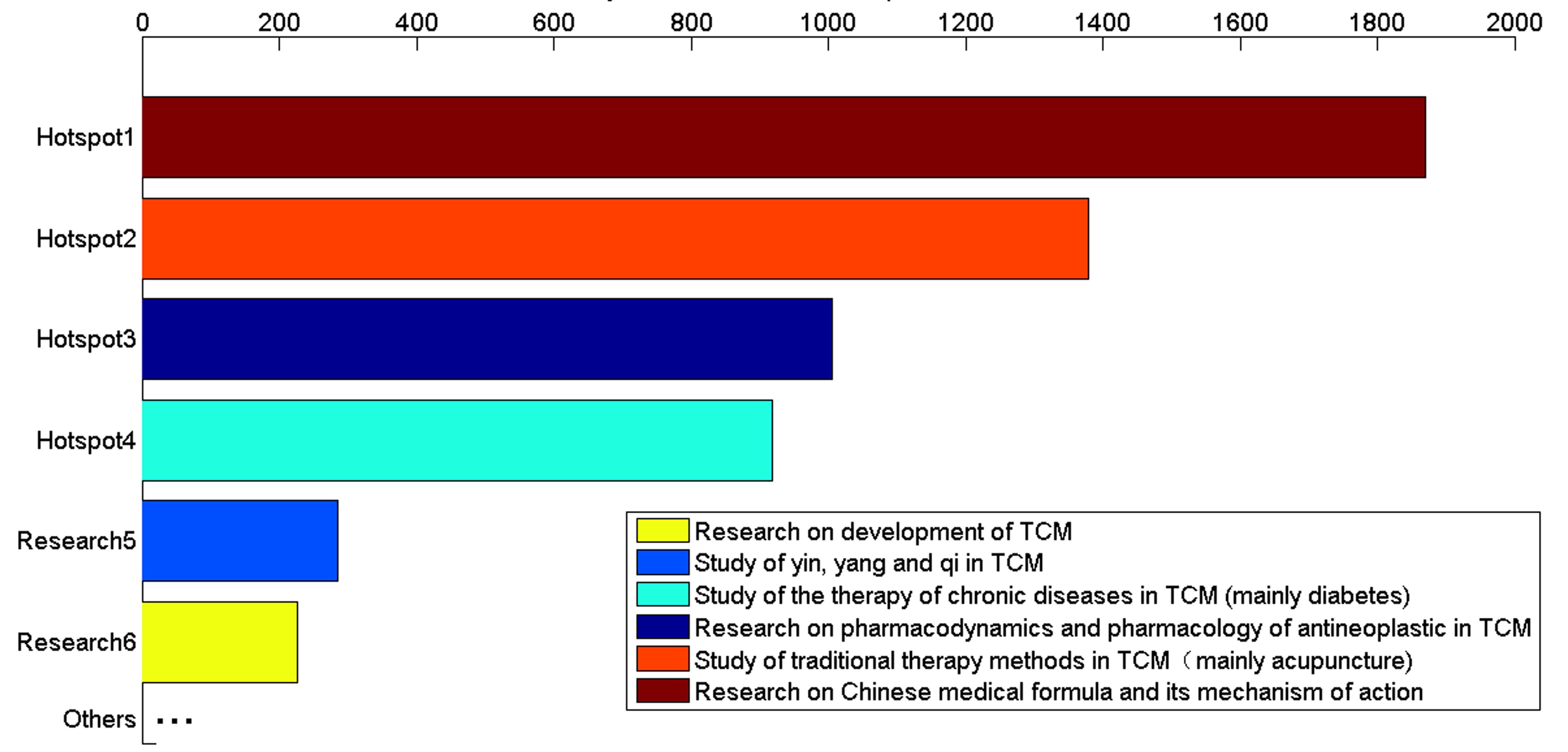
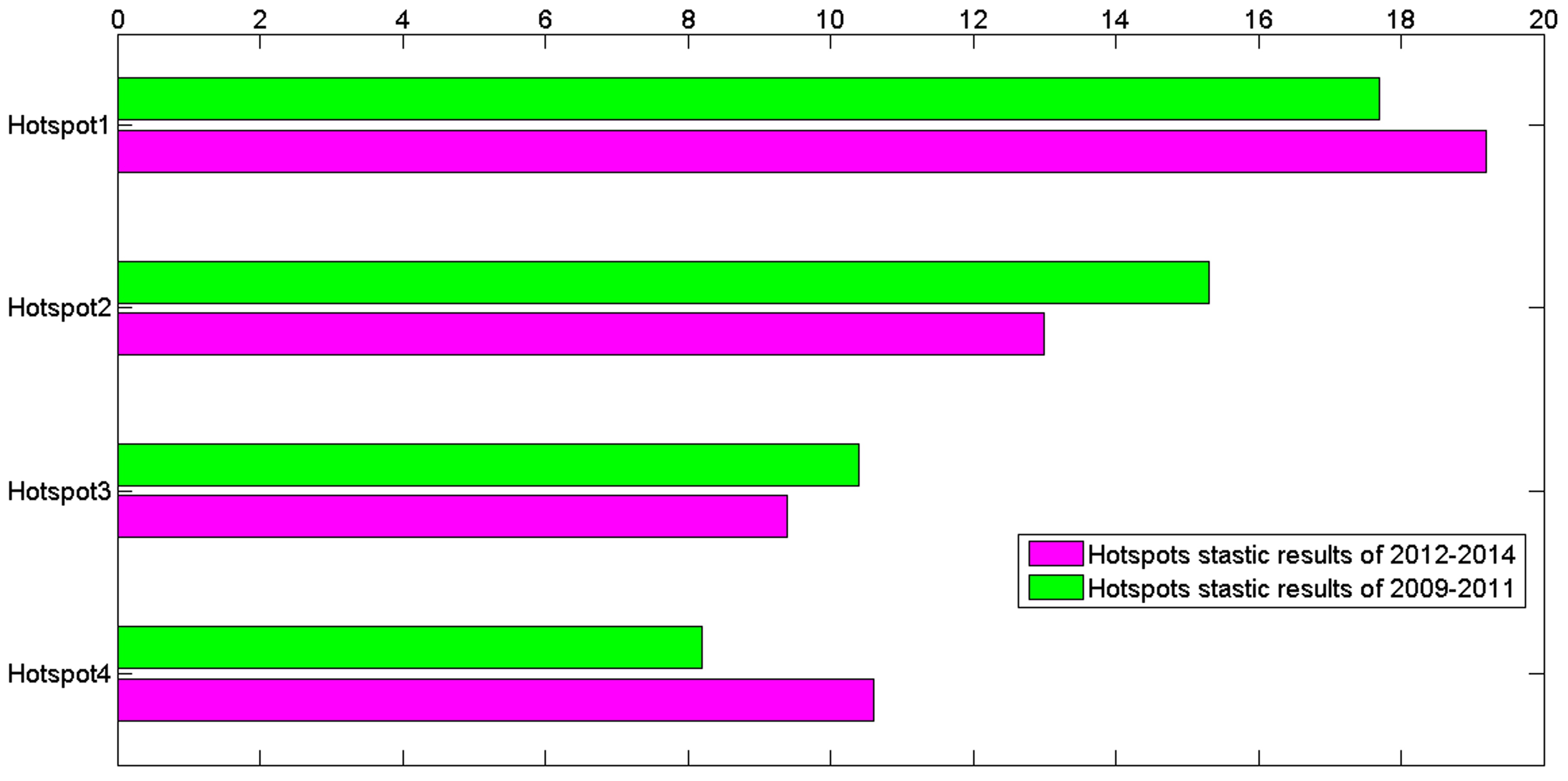
From another perspective, TCM researches not only interest in the research hotspot during a certain period, but also concern the hotspots transfer in the next few years. So we also perform the experiments to explore the changes and development trends of hotspots on TCM field. There are 6076 articles from 2009 to 2011 and 6469 articles from 2012 to 2014. We take the methods mentioned above and compare the hotspots of the former 3 years and the latter 3 years. We find the main hotspots of the former three years and the latter three years are unchanged, but some slight transfer can be discovered. According to the percentages of articles on different hotspots in whole dataset of every three years, we illustrate the articles distribution on different hotspots from 2009 to 2011 and 2012 to 2014.
In figure 6, the bars denote the percentage of articles on different hotspots in whole dataset of every three years. Hotspot1 represents research on Chinese medical formula and its mechanism of action. Hotspot2 denotes research on pharmacology and pharmacodynamics of antineoplastic agent in TCM. Hotspot3 is research on the therapy of chronic diseases in TCM. Hotspot4 refers to research on traditional therapy methods in TCM. As time passed by, it is obvious that researchers tend to pay more attention on study of Chinese medical formula and its mechanism of action, and research on traditional therapy methods in TCM. Moreover, research on traditional therapy methods in TCM is increasing rapidly, it catches up with and surpasses the research on the therapy of chronic diseases in TCM. In summary, the dynamic development of TCM in past six years can be easily gained from figure 6.
DISCUSSION
But there are still some limitations of our research. Firstly, the results we derived are almost words or phrases. There are still some difficulties to conclude sentences which can reflect the hotspots information. In most cases, our hotspots detection schemes need the expert domain knowledge and practical experience to summarize final results. Thus our research still cannot detect hotspots completely automatically without any manual intervention in some ways. In the future research, prior knowledge based hotspot detection should be developed to improve the current system. Meanwhile, it should further discuss that whether the five year span of the experiment data is appropriate or not. However, it is really meaningful for us to study the variation trends with data in different time spans.
CONCLUSION
ACKNOWLEDGMENT
REFERENCES
- Thornton PK, Jones PG, Owiyo T, Kruska RL, Herrero M, et al. (2008) Climate change and poverty in Africa: Mapping hotspots of vulnerability. African Journal of Agricultural and Resource Economics 2: 24-44.
- Gimona A, Dan van der Horst (2007) Mapping hotspots of multiple landscape functions: a case study on farmland afforestation in Scotland. Landscape Ecology 22: 1255-1264.
- Boyack KW (2004) Mapping knowledge domains: Characterizing PNAS. Proc Natl Acad Sci, 101: 5192-5199.
- Steinbach M, Karypis G, Kumar V (2000) A comparison of document clustering techniques. KDD workshop on text mining 400: 525-526.
- Congnan Luo, Yanjun Li, Soon M Chung (2009) Text document clustering based on neighbors. Data & Knowledge Engineering 68: 1271-1288.
- Wang C, Zhang M, Ma S, Ru Liyun (2008) Automatic online news issue construction in web environment. Proceedings of the 17th international conference on World Wide Web, USA. ACM: 457-466.
- Nowell L, Schulman R, Hix D (2002) Graphical encoding for information visualization: An Empirical Study. Proceedings of the IEEE Symposium on Information Visualization: 43- 50.
- Daniel A Keim (2002) Information Visualization and Visual Data Mining. IEEE Transactions on Visualization and Computer Graphics 8: 1-8.
- TT He, GZ Qu, SW Li, XH Tu, Zhang Y, et al. (2006) Semi-automatic hot event detection. Advanced Data Mining and Applications: 1008-1016.
- N Li, DD Wu (2010) Using text mining and sentiment analysis for online forums hotspot detection and forecast. Decision Support Systems 48: 354-368.
- Haribhakta Y, Malgaonkar A, Kulkarni P (2012) Unsupervised topic detection model and its application in text categorization. Proceedings of the CUBE International Information Technology Conference. ACM: 314-319.
- Kim BY, Kang JS, Han JS, Jeon WK (2014) Mapping the dementia research area at the micro-level using co-terms analysis and positioning for traditional herbal medicine. Chin J Integr Med 20: 706-711.
- Matsuo Y, Ishizuka M (2004) Keyword extraction from a single document using word co-occurrence statistical information. International Journal on Artificial Intelligence Tools 13: 157-169.
- Peng C, Wei Z (2012) Co-word Analysis of Domestic Network Virtual Society Research Hotspots and Evolution. Management of e-Commerce and e-Government (ICMeCG), 2012 International Conference on. IEEE: 327-331.
- Yung-Shen Lin, Jung-Yi Jiang, Shie-Jue Lee (2014) A similarity measure for text classification and clustering. IEEE Transactions on Knowledge & Data Engineering 26: 1575-1590.
- Bradford RB (2008) An Empirical Study of Required Dimensionality for Large-scale Latent Semantic Indexing Applications. Proceedings of the 17th ACM conference on Information and knowledge management. ACM: 153-162.
- Ma J, Xu W, Sun Y, Turban E, Wang S, et al. (2012) An Ontology-Based Text-Mining Method to Cluster Proposals for Research Project Selection. IEEE Transactions on Systems, Man and Cybernetics, Part A: Systems and Humans 42: 784-790.
Citation: He C, Zhao C, Li GZ (2015) Hotspot Detection in Traditional Chinese Medicine Based on PubMed. J Altern Complement Integr Med 1:006.
Copyright: © 2015 Chong He, et al. This is an open-access article distributed under the terms of the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original author and source are credited.