Perception of Deep Band Modulated Speech in the Presence of Noise by Elderly Individuals with Hearing Impairment
*Corresponding Author(s):
Hemanth Narayan ShettyProfessor In Audiology, Department Of Audiology, JSS Institute Of Speech And Hearing, Mysore, Karnataka And India 570004, India
Tel:+91 998651550,
Email:hemanthn.shetty@gmail.com
Abstract
Background: Deep band modulation (DBM) is an envelope enhancement strategy that enhances temporal modulation and may provide a cue for speech understanding among individuals who suffer from temporal processing deficits.
Objective: To investigate the effect of deep band modulation on phrase recognition scores at different signal-to-noise ratios (SNRs) among older adults having hearing loss classified as good and poor performers based on temporal resolution ability.
Method: Phrase recognition score was obtained for unprocessed and DBM phrases at three SNRs (4, 5, and - 4 dB signal to noise ratio) in 25 (age range 60 to 82 years, mean age 71.48 years) older adults having bilateral mild to moderately severe sloping sensorineural hearing loss. In addition, the gap detection test was also administered to the study participants.
Results: A significant better recognition score was obtained in DBM than the unprocessed phrase. The magnitude of improvement from DBM was not the same in all the participants. Thus, the participants were classified into good and poor performers based on their temporal processing ability. The mean unprocessed and DBM phrase recognition scores in each SNR were higher for good performers than the poor performers. The benefit of deep band modulation was evident for the good performers, especially at high SNR, which was moderately correlated with age and temporal processing ability.
Conclusion: The benefit from DBM on recognition score for the good performers is predicted from the temporal resolution abilities and age. However, the benefit is minuscule for the poor performers in noise.
Introduction
The audibility of consonants is critical for speech perception [1]. Age-related hearing loss at high frequencies reduces the consonants’ audibility, thereby impairs speech recognition [2]. Temporal processing refers to the processing of acoustic stimuli over time. The gap detection threshold is one of the tests to measure the temporal processing ability. Gap detection threshold is the ability of the person to detect the minimum gap in noise. Strouseet al.[3] demonstrated a poorer temporal processing ability reflected in the gap detection test (GDT) in elderly listeners exhibit. The gap detection threshold is linked to the person’s ability to process the rapid and or short time events related to distinction in speech [4].De Filippo and Snell [5] reported that those who can distinguish voice and voiceless conjugate and manners of speech sounds had a lower threshold (in ms) in GTD and vice versa. It is reasonable to consider that in addition to peripheral hearing loss in older adults, the temporal processing impairment accounted for speech recognition impairment.
Understanding speech in poor Signal-to-Noise Ratio (SNR) is a significant challenge for hearing-impaired listeners [6]. The difficulty arises from deficits in temporal processing and wider auditory filters [7]. It is well-established evidence that listeners with hearing impairment understand the speech through the maximum amplitude of envelope in the signal, partly buried in noise [6]. Shannon et al. [8] made the older hearing-impaired adults rely primarily on envelope cues in the absence of spectral cues by modulating the noise with respect to the speech envelope. The result revealed that the older hearing-impaired adults recognized the speech by temporal envelope cues of higher amplitude. This was attributed to the release of temporal cues from masking at high SNRs [9].
Several temporal enhancement strategies are developed to improve speech perception in noise. Earlier studies have used simple power-law function [10], envelope expansion nonlinearity schema [11] and envelope compression and expansion method [12] to extract temporal envelope of speech. The speech recognition score results for the signals with enhanced temporal envelope using the above algorithm have shown equivocal results in older adults with hearing loss [10-12]. Deep band modulation (DBM) is one such strategy developed by Nagarajan et al [13]. DBM is similar to the speech envelope enhancement schema [14] except for the time-scale of expansion, envelope filtering, and channel profile gain. These three modifications in DBM increase the consonant to vowel ratio and modulation depth. In DBM, the extracted temporal envelope bandwidth between 3 and 30 Hz from each channel is enhanced by 15 dB, which significantly increases the modulation depth and the masking of a consonant by a vowel is minimized. After perceptual training, this strategy was beneficial for learning disabled children likely to suffer from temporal processing impairment [13]. Shetty and Mendhakar [15] studied the phrase perception using DBM scheme in older adults at different signal-to-noise ratios. The results revealed that the deep band modulated phrase perception scores from different SNRs in the older adult group were close to the unprocessed phrase perception scores in the younger adult group. To reduce bias in the stimulus redundancy, Shetty and Kooknoor [16] had utilized deep band modulated VCV syllables on consonant identification scores and determined the transfer of features such as place, manner, and voicing. At reduced SNRs, cues from DBM enabled the listener to repeat the heard VCV syllables. DBM partly lessens aging and the combined effects of aging and hearing loss through the temporal enhancement approach. To purport, DBM compensates for temporal asynchrony in older adults and alleviates the perception problem from noise. The temporal processing impairment may not be the same in individuals with the same degree of hearing loss. Shetty and Kooknoor [16] empirically demonstrated a strong negative correlation between DBM phrase perception and gap detection threshold in older adults with hearing loss.
Evidence exists that the exaggeration of speech envelope by deep band modulation may enhance intelligibility [17]. However, a comprehensive evaluation of the interaction of envelope enhancement algorithms with aging and hearing loss is scanty. The deep band modulated enhancement algorithm used to enhance the envelope was applied to phrase-level-stimuli in different background noise conditions (-4 dB SNR, 0 dB SNR and 4 dB SNR) among older adults and younger adults with and without hearing loss (Hemanth, 2020 review). The findings revealed that perception from the deep band modulated phrases lessens the combined effect of aging and hearing loss. Deep band modulation provides access to an essential cue for speech understanding for older adults with hearing loss who often suffer from temporal processing deficits. Now the question arises: ‘Is the phrase perception scores from DBM comparable irrespective of temporal processing impairment?’The goal is to identify the importance of enhanced temporal envelope in challenging communication situations among older adults having a different degree of temporal resolution ability to understand speech. It is hypothesized that auditory temporal processing abilities are critical for understanding speech, and deep band modulation may benefit, especially in those with poor temporal processing ability. The present study aimed to investigate deep band modulation and noise on the perception of phrases in older adults with hearing loss. The following objectives were formulated:
1) To compare phrase recognition at each SNR a) between unprocessed and deep band modulated conditions from participants of the study and b) between good and poor performers in DBM and UP conditions
2) To find the relationship between recognition scores in DBM condition, gap detection threshold and aging and
3) Predict the benefit of DBM phrase recognition from temporal processing ability and aging.
Material And Methods
A repeated measures design was utilized to investigate the effect of deep band modulated phrase perception at different signal-to-noise ratios among older adults with hearing loss.
Subject selection criteria
A total of 25 participants with bilateral mild to moderately severe sloping sensorineural hearing loss within the age range of 60 to 82 years (mean age, 71.48 years) were recruited for the present study. The sloping hearing loss was operationally defined as a threshold from 250 Hz to 500 Hz is being ≥ 20 dB HL, 1000 Hz to 2000 Hz is being ≥ 40, and from 3000 to 8000 Hz is being ≥ 65 dB HL. All the participants had normal middle ear status, having an ‘A’ type tympanogram. Participants were native speakers of Kannada, an Indian language. The Mini-Mental State Examination was used to rule out cognitive deficits, and those who scored between 24 and 30 were recruited [17]. All the test procedures were approved by the human Ethics committee of the JSS Institute of Speech and Hearing (JSSISHA/EC/103). The procedures involved in the study were non-invasive, and all the procedures were explained to the participants before testing. Written informed consent was obtained from each participant or a member of their immediate family before participation.
Gap detection threshold
The gap detection threshold is the ability to detect rapid changes in a signal over time, reflecting the temporal resolving power of the auditory system [18]. Older individuals with hearing loss often exhibit subtle temporal processing impairment [19]. Therefore, the gap detection threshold (GDT) test was performed to assess temporal resolution from all participants. Each stimulus is comprised of three segments of broad noise; having a duration of 500 ms. A brief temporally centered gap was introduced randomly in one of the noise segments. The initial gap duration was 20 ms, and it was adjusted in 0.5 ms steps. The stimulus was generated in MATLAB 2015 b (Mathworks, Natick, Massachusetts, USA) at a sampling rate of 22000 Hz. The generated stimuli were routed through an audiometer to headphones binaurally at 35 dB SL [20]. The task was to detect a brief pause in broadband white noise. The detection threshold was estimated using a three alternative forced-choice method (3-AFC), a two-down one-up adaptive procedure [21]. The adaptive tracking procedure stopped after 12 reversals, and the threshold was obtained by averaging the gap-duration values of the last four reversals.
Preparation of deep band modulated phrases
Standardized phrase lists developed by Shetty and Mendhakar [22] were utilized to study phrase recognition. The six equivalent lists were phonetically balanced, comprised of 10 phrases in each list. Each phrase is containing two words with an average duration of 1500 ms. A total of three equalized phrase lists were utilized to prepare a deep band modulated (DBM) version of lists. Praat software (version 4.6.09) (Free computer software, Amsterdam, Netherlands) was used to apply the algorithm adopted by Nagaraja et al [13]. A detailed description of the DBM algorithm is provided at http://www.fon.hum.uva.nl/praat/manual/Sound Deepen_band_modulation.html. Each phrase was passed through 20-s order Butterworth filters by the filter bank method. The center frequencies from these 20 filters were logarithmically spaced between 100 Hz and 10 kHz. From the output of each narrowband channel, an envelope was extracted (i.e., Hilbert transform was computed using Fast Fourier Transform). The envelope in each narrowband channel was filtered using a second-order Butterworth filter with cut-off frequencies between 3 and 30 Hz [23] and was rectified. The processed Hilbert envelope was then recombined with the original temporal fine structure. Before summating the envelope from each channel, a gain of 15dB [23] was provided for the channels within the frequency range of 1 - 4 kHz to achieve the resultant deep band modulated phrase.
Generation of noise and mixing of derived noise
The phrases from different lists were selected randomly and concatenated. The Fast Fourier Transformer (FFT) was performed on the concatenated phrases. The spectral content of randomized phrases was converted back into a ‘.wav’ file by inverse FFT to derive the Long-Term Average Speech Spectrum (LTASS). A similar procedure was carried out to derive noise from the deep band modulated phrases. The generated speech-shaped noise with a simple FIR filter matched the speaker spectrum for the target phrase stimulus, as given by Versfeld [24].
Each of the three lists of DBM phrases was embedded at three different SNRs (-4, 0, and 4 dB SNR). The 50 % recognition score was obtained at - 4 dB SNR for the phrase stimuli in the sigmoid curve [15]. It is a well-established fact that the combined effect of digital noise reduction and directionality reduces the annoyance by 4 dB SNR [25]. Therefore, the SNRs of -4dB, 0dB and 4dB were considered in the present study.
The DBM phrase spectrum-shaped noise was digitally mixed with the phrases to generate different SNRs relative to the RMS value of the phrases (Figure 1). Noise onset preceded the onset of a phrase by 300 ms and continued until 300 ms after the end of the phrase. The noise was ramped using the cosine square function with ramp duration of 100 ms. The onset of noise before the phrase is believed to guard against unintended onset effects. This procedure to mix noise at different SNRs was repeated for another three phrase lists in an unprocessed condition. Figure 1 shows that amplitudes of consonants were relatively increased in the deep band modulated phrase than the UP phrase in quiet and at different SNRs. In addition, the modulation depth was more in DBM than in the UP condition.
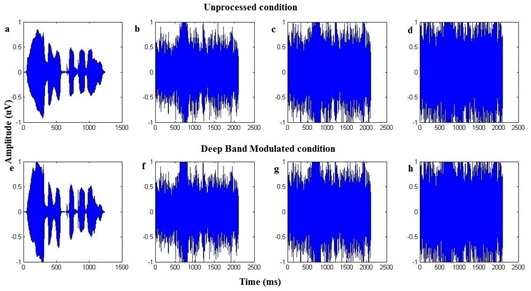 Figure 1: Outputs for the ‘o:duvakudure’, showing unprocessed phrases in quiet (a), 4 dB SNR (b) 0 dB SNR (c), and - 4 dB SNR (d), in first row. In the second row, the deepen band modulated phrases in quiet (e), 4 dB SNR (f), 0 dB SNR (g), and - 4 dB SNR (h) are represented.
Figure 1: Outputs for the ‘o:duvakudure’, showing unprocessed phrases in quiet (a), 4 dB SNR (b) 0 dB SNR (c), and - 4 dB SNR (d), in first row. In the second row, the deepen band modulated phrases in quiet (e), 4 dB SNR (f), 0 dB SNR (g), and - 4 dB SNR (h) are represented.
Listening condition
The phrase recognition task was carried out in an acoustically treated room, where the ambient noise level was within the permissible limits (ANSI, 1999). Phrase recognition in unprocessed and deep band modulated conditions was assessed from study participants in each of the three SNRs. A total of six lists [2* conditions (UP and DBM) and 3* SNRs (-4, 0, and 4 dB SNR)] were stored on a personal laptop connected to the auxiliary input of an audiometer. The output of the audiometer was routed through TDH-39 headphones binaurally. It was ensured that the average deflection on the volume unit (VU) meter was at 0 dB during the presentation of the stimuli. The ten phrases from each list were randomly presented at the most comfortable level at the specified SNRs. Each participant was instructed to repeat the phrase heard. The presentation of the phrase under different experimental conditions (2* and 3* SNRs) was counterbalanced across participants using a table of random digits to control the order effect. An investigator manually assigned one mark for correct identification of each target word in each phrase, such that the maximum marks assigned for each experimental condition was 20. A score of zero was awarded if the participant did not repeat/partly repeat a word in the phrase. Participants were given sufficient breaks during the testing. The testing duration per participant was approximately 30 minutes.
Results
The mean and standard deviation of phrase recognition scores for unprocessed and deep band modulated phrases at different SNRs are presented in Table 1. It can be observed from the table that the recognition score for deep band modulated speech was better than those for an unprocessed speech at different SNRs. The recognition score in the DBM condition over the UP condition was less for -4 dB SNR followed by 0 dB SNR and 4 dB SNR. To evaluate the effect of conditions (unprocessed and deep band modulated conditions) in different SNRs (-4, 0, and 4 dB SNR), a two-way analysis of variance (ANOVA) for repeated measures was performed. There was a significant main effect of conditions (F (1, 24) = 117.00, p = 0.000) and SNRs (F (2, 48) = 31.45, p = 0.000) on phrase recognition scores. There was a significant interaction between the conditions and SNRs (F (2, 48) = 3.39, p = 0.042). Bonferroni pair wise comparison revealed that the mean phrase recognition scores increased significantly as the SNR increased (p < 0.01). As there was an interaction between the condition*SNR, separate one-way ANOVAs were performed for unprocessed and deep band modulated conditions. Results revealed a significant main effect of listening condition at different SNRs for both unprocessed (F (2, 48) = 15.76, p = 0.000) and deep band modulated speech (F (2,48) = 28.25, p = 0.000). Scheffe’s post hoc analysis for unprocessed speech revealed that mean phrase recognition scores in 4 dB SNR was significantly different from all the SNRs (0 dB SNR and - 4 dB SNR) (p <0.01).The mean phrase recognition score at 0 dB SNR was significantly different from -4 dB SNR (p <0.01). Scheffe’s post hoc analysis for deep band modulated speech revealed no significant difference between mean phrase recognition scores obtained in 4 dB SNR and 0 dB SNR conditions. Still, the rest of the conditions differed significantly (p <0.01) from each other.
|
Groups |
Deep band modulated condition |
Unprocessed condition |
||||
|
|
- 4 dB SNR |
0 dB SNR |
4 dB SNR |
- 4 dB - SNR |
0 dB SNR |
4 dB SNR |
|
Participants of the study N = 25 |
7.60 (3.26) |
11.28 (4.79) |
11.56 (4.85) |
3.28 (1.51) |
5.52 (3.38) |
5.84 (2.26) |
|
Good performers N=14 |
9.28 (2.30) |
13.28 (3.31) |
15 (2.90) |
3.85 (1.46) |
7.14 (2.79) |
7.42 (3.27) |
|
Poor performers N=11 |
5.45 (3.11) |
6.72 (2.34) |
7.45 (1.84) |
2.54 (1.29) |
3.45 (0.94) |
3.87 (1.24) |
N = number of participants; SNR - signal to noise ratio
Table 1: Mean and standard deviation of recognition score in two listening conditions at each SNR.
The gap detection threshold data inspection showed a mean value of 12.30 ms with an SD of 4.88 ms. Although all the study participants had mild to moderately severe sloping sensor neural hearing loss, the GDT ranged 15 ms with a minimum value of 5 ms and a maximum of 20 ms. It was imperative to consider the influence of temporal processing ability on recognition. A few individuals in whom the score at 4 dB SNR in unprocessed condition was already poor, the magnitude of deterioration in performance because of the less SNR is even poorer due to floor effect. Schneider and Pichora-Fuller [26] have reported impaired speech perception in whom the temporal resolution was reduced in older adults. Therefore, for further analysis, the data were divided into two groups, namely Good Performers (mean = 8.41 ms SD = 2.46) (those who scored less than 10 ms in GDT) and Poor Performers (mean = 17.18 SD = 1.60) (those who scored > 10 ms in GDT). Grouping the participants based on temporal resolution skills helped to document the magnitude of the benefit received when the test stimuli were enhanced using a deep band modulation algorithm. The magnitude of improvement observed was not the same in all the participants. For poor performers, those with very low phrase recognition scores for the unprocessed speech showed minimal or no improvement with deep band modulation at each of the SNRs.
A two-way (listening condition and SNR) repeated-measures ANOVA with between-subject factor as a group (good and poor temporal processing ability) was performed to evaluate the effect of listening conditions (unprocessed and deep band modulated conditions) in different SNRs (-4, 0, and 4 dB SNR) on phrase recognition. The analysis showed a significant main effect of listening condition (F (1, 23) = 215.06, p = 0.001) and stimuli (F (2, 46) =39.05, p = 0.001) on phrase recognition scores. Besides, there was a significant difference between groups on recognition (F (1, 23) =27.88, p = 0.001). An interaction between the listening condition and SNR on recognition was found significant (F (2, 46) = 3.12, p = 0.001). We analyzed the data of recognition scores between unprocessed and DBM conditions using paired-samples t-test in each of the SNRs for good and poor performers separately. Results of the dependent samples t-test revealed a significant improvement in the phrase recognition in the DBM condition than the unprocessed condition at each of the SNRs for both good and poor performers (p<0.001) (Table 2).
|
Groups |
Good performers df =13 |
Poor performers df = 10 |
||
|
SNR |
p value |
t value |
p value |
t value |
|
- 4 dB SNR |
-9.50 |
0.001 |
-3.95 |
0.003 |
|
0 dB SNR |
-9.20 |
0.001 |
-6.05 |
0.001 |
|
4 dB SNR |
-12.68 |
0.001 |
-4.27 |
0.002 |
DF - Degree of Freedom
Table 2: p-value and t value of dependent samples t-test performed between listening conditions (UP and DBM) on speech recognition at each SNR
It can be observed from Figure 2 that the effect of noise on the magnitude of improvement in recognition of DBM over unprocessed conditions was not the same at all the SNR for both good and poor performers. The magnitude of improvement in recognition of DBM over unprocessed condition recognition score was significantly increased at 4 dB SNR than -4 dB SNR in good performers (t (13) = 2.87, p<0.001). In the rest of the comparisons between SNRs, the benefit from DBM over unprocessed conditions was almost the same in each group.
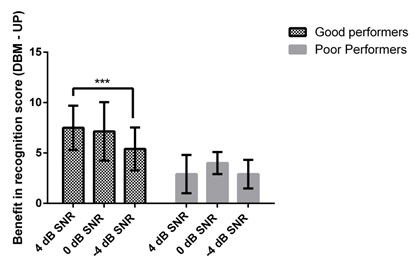 Figure 2: Benefit in the recognition score at each of the SNRs from the good and poor performers.
Figure 2: Benefit in the recognition score at each of the SNRs from the good and poor performers.
The correlation coefficient (Table 3) was computed between age and phrase perception score in each experimental condition using the Pearson product-moment correlation. The Pearson correlation coefficient results revealed a significant negative correlation between age and phrase perception score in DBM listening conditions at each SNR. It indicates that the phrase recognition score reduces with age increases (Figure 3 a,b,c,d, e f).
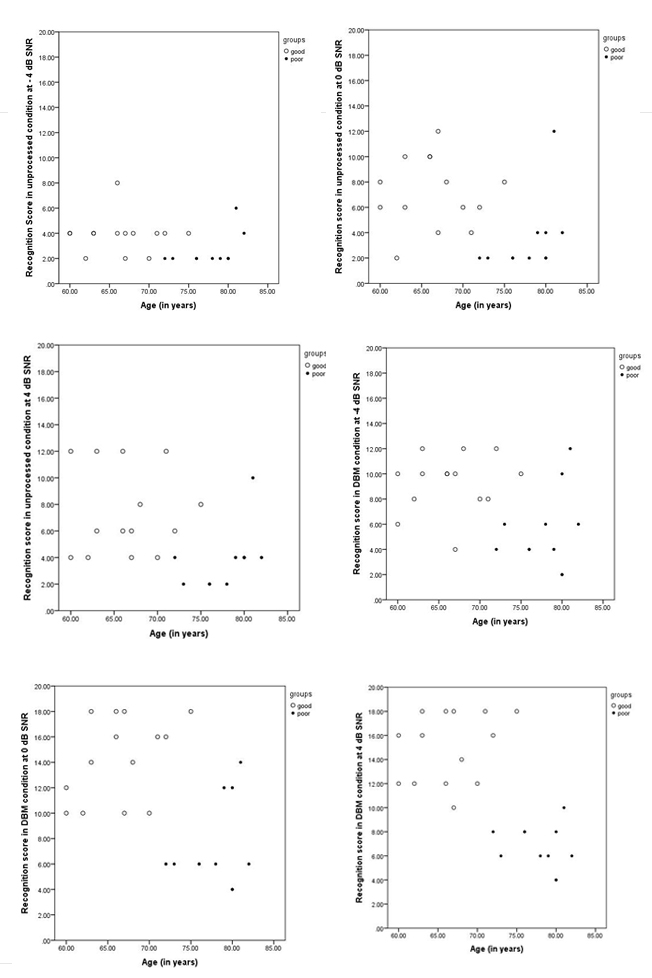 Figure 3: Representing scatter plot between age and phrase perception score at each SNR in both (a) UP and (b) Deepen band modulated conditions.
Figure 3: Representing scatter plot between age and phrase perception score at each SNR in both (a) UP and (b) Deepen band modulated conditions.
|
|
Age (in years) |
Gap detection threshold (in ms) |
||
|
Correlated measures #(N=25) |
Significance level (p) |
Correlation coefficient (r) |
Significance level (p) |
The correlation coefficient (r) |
|
Unprocessed condition |
|
|||
|
-4 dB SNR |
0.164 |
-0.287 |
0.042 |
-0.409* |
|
0 dB SNR |
0.064 |
-0.376 |
0.011 |
-0.500* |
|
4 dB SNR |
0.055 |
-0.388 |
0.002 |
-0.596** |
|
Deep band modulated condition |
|
|||
|
-4 dB SNR |
0.047 |
-0.401* |
0.007 |
-0.527** |
|
0 dB SNR |
0.023 |
-0.454* |
0.001 |
-0.659** |
|
4 dB SNR |
0.001 |
-0.674** |
0.001 |
-0.807*** |
SNR - Signal to noise ratio
#number of participants;
*0.31 until 0.50 or -0.31 until -0.50 = weak;
**0.51 until 0.70 or -0.51 until -0.70 = moderate;
***0.71 until 0.90 or -0.71 until -0.90 = strong;
Table 3: Results of Pearson product-moment correlation.
Furthermore, the correlation coefficient (Table 3) was computed between GDT and phrase perception score in each experimental condition using the Pearson product-moment correlation. The Pearson correlation coefficient results revealed a significant negative correlation between GDT and phrase perception scores in two unprocessed and DBM listening conditions at each SNR. It indicated higher GDT values in individuals with lower phrase perception scores (Figure 4).
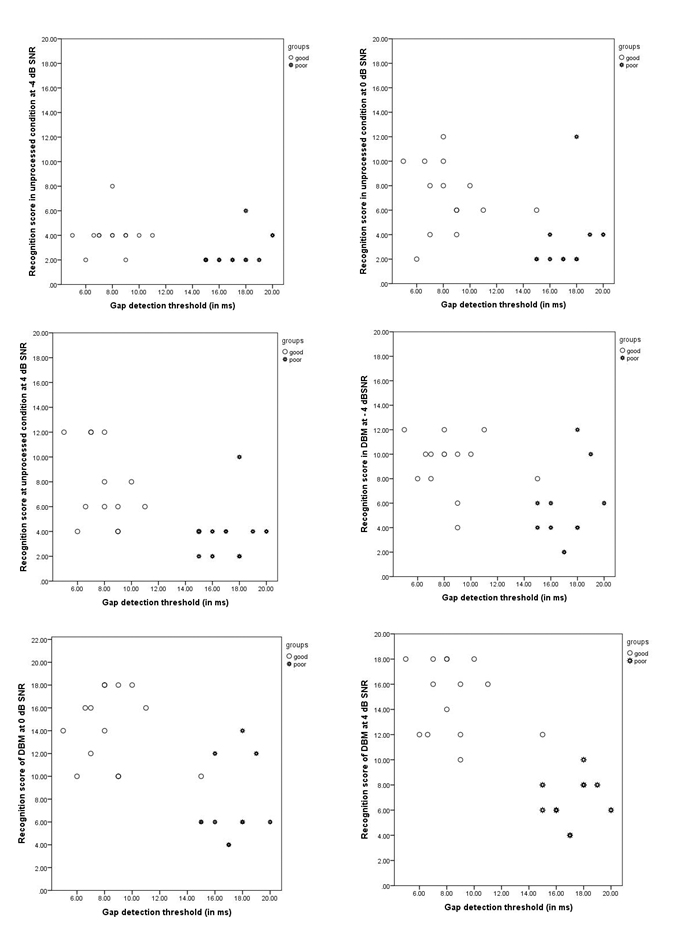 Figure 4: Representing the scatter plot between GDT and phrase perception score at each SNR in both (a) UP and (b) Deepen band modulated conditions.
Figure 4: Representing the scatter plot between GDT and phrase perception score at each SNR in both (a) UP and (b) Deepen band modulated conditions.
The benefit was calculated by subtracting the score of DBM from the unprocessed score in each of the experimental conditions. The correlation coefficient was computed between benefit from DBM, age, and GDT at each SNR using the Pearson product-moment correlation. The Pearson correlation coefficient results revealed that there was a significant moderate negative correlation between benefit received from DBM: and age (N =25, r = -0.610, p= 0.001) and GDT (N =25, r = -0.593, p= 0.002) at 4 dB SNR. The multiple correlation coefficients R is 0.622, which indicates a good level of prediction. The r2 is 0.386, that is, 38.6% variance in the benefit received from DBM can be explained by the age and their temporal processing ability as reflected in the GDT. The age and GDT significantly predicted the benefit received from the DBM, [F (2, 22) = 6.925, p=0.005] indicative of the model is a good fit for the data. The regression equation is utilized to predict the benefit of DBM = 20.335 -0.179*(age) - 0.166 (GDT).
Furthermore, a moderate negative correlation was seen between benefit and GDT at 0 dB SNR (N =25 r = -0.487, p= 0.014) and at -4 dB SNR (N =25 r = -0.431, p= 0.032) but there was no correlation with the age. A linear regression established a temporal processing ability reflected in GDT could significantly predict the benefit received from DBM at 0 dB SNR [F (2, 22) = 7.152, p=0.014] and -4 dB SNR [F (2, 22) = 5.238, p=0.032], respectively. The temporal processing ability accounted to 23.7 % and 18.5 % of the explained variability to predict the benefit of DBM recognition for 0 dB SNR and -4 dB SNR. The regression equation is utilized to predict the benefit of DBM = 9.465 -0.301*(GDT score) for 0 dB SNR and for -4 dB SNR the benefit of DBM =7.101 -0.226*(GDT score).
Discussion
The phrase recognition scores increased significantly as the SNR increased from -4 to 4 dB SNR, irrespective of conditions. The mean phrase recognition was better in deep band modulation than in the unprocessed condition. It can be reasoned that enhancing the consonant portion of speech and compressing the vocalic portion may have improved the listeners’ ability to process the slow modulation envelope of phrases (3 - 30 Hz). In addition, the modulation depth enhanced by 15dB was beneficial and made the temporal cues more resistant though obscured by noise. The unprocessed phase recognition at 4 dB was found significant than 0 dB SNR and -4 dB SNR. In addition, the recognition score at 0 dB SNR was significantly better than -4 dB SNR. However, in DBM, the phrase recognition at 4 dB SNR is relatively better than 0 dB SNR reached no significant difference but was found significant compared to the recognition score between -4 dB SNR and 4 dB SNR. This might be attributed to the improved accessibility of temporal cues in the DBM condition than the unprocessed condition. At high SNR, the greater amplitude modulation in DBM may have lead to momentary fluctuations that were not energetically masked.
When the aggregate data was analyzed, a few individuals in whom the score at 4 dB SNR in unprocessed condition was already poor, the magnitude of deterioration in performance was even poorer because of the lesser SNRs yields floor effect. Besides, the recognition of unprocessed speech has no relation with the age of the participants, irrespective of SNRs. However, the speech recognition score worsened due to an increased threshold in temporal resolution ability and it is valid for SNR. To deduce the floor effect by noise, recognition of phrase has no relation with age but found a relation with temporal resolution ability made to rethink sub grouping the cohort. Thus, we have sub-grouped the data into good and poor performers based on the gap detection threshold to confirm the effect of the DBM condition on the recognition score in the presence of noise.
In each of the SNRs, it was found that the phrase perception score was significantly better in DBM than the unprocessed condition, irrespective of group. This could be due to the fluctuation in speech, and noise was compared across the output of auditory filters to recognize the speech [27]. The DBM of higher amplitude fluctuations at the output of a few auditory filters corresponding to the frequencies of the target phrases was distinct from the modulation patterns of the speech-shaped noise. This disparity in the modulation patterns across different auditory filters is sensitive to detect the signal leading to masking release [28]. Whereas in unprocessed conditions, the fluctuation in phrase and speech-shaped noise may be filled evenly across the output of auditory filters left with no distinct pattern for release from masking. Besides temporal and spectral variations of speech-shaped masking noise derived by phrases is closer to that of the target phrase, where listening through available dips was less likely.
Furthermore, in each group, we computed the benefit by subtracting the scores of DBM from the unprocessed condition. When we assessed the benefit as a function of SNR in each group, surprisingly, the benefit was partial out in the presence of noise, especially in poor performers. One possible speculation could be that individuals with poor temporal processing impairment reflected in high threshold in GDT have failed to extract available higher amplitude envelopes, which are partly masked by noise. Whereas, in good performers, the benefit at 4 dB SNR was significantly better than - 4 dB SNR, but the benefit reached no difference between 0 dB SNR and -4 dB SNR. The amount of benefit obtained from DBM over UP is negligible, especially at reduced SNRs. This is because at 0 dB NSR and -4 dB SNR, there would be a significant reduction in modulation depth in the phrase. In addition, noise distorts the temporal fine structures and obliterates envelope cues for identification. Though good performers had relatively good temporal processing ability than poor performers, they cannot follow a speech by extracting the momentary fluctuations in the temporal envelope. To conclude, when recognizing the DBM phrase in the presence of background sounds, time-frequency regions conveying useful information about the processed phrase are relatively more in higher SNR than at reduced SNR by an increase of modulation depth in those regions. In poor performers, the available modulation of the processed phrase is limited and or buried in the background noise may find it challenging to recognize the available modulation depth due to reduced temporal resolution ability.
The regression model was constructed to predict the benefit of DBM from temporal resolution and age. We can predict a higher benefit in recognition from the DBM condition when the resultant signal strength is higher than the noise. For every one-year increase in age among the older adult, the recognition score decreased by 0.2 %. If the threshold in GDT reduces by 1 ms, then the recognition increases by 0. 15 %. Overall, if the older adults’ age is less and the GDT threshold is low, the combined affect on the recognition score increases by 0.25 %. However, suppose the strength of the signal is equal to or less than noise. In that case, the recognition score of DBM depends on temporal resolution ability rather than the age of the individuals. The auditory temporal processing abilities are critical for understanding speech processed by the deep band modulation at the adverse listening condition.
The observed benefit in the phrase recognition performance induced by the proposed deep band modulation was found in good performers. Further research is needed to establish the benefit of DBM in multi-talker noise, where the modulation depth may vary in relation to speech. Modulation of the background sounds may become difficult to detect with an increase in the modulation depth in the phrase, especially when loudness recruitment in them close to its asymptotic value of the internal modulation depth and near-saturation of fluctuation strength [29]. Thus, it may be imperative to perform the psychoacoustic measures (such as temporal envelope detection and discrimination) and substitute the same threshold to enhance the depth of the target phrase, which may help understand the speech in the presence of noise especially for poor performers.
Conclusion
To conclude, a temporal enhancement strategy such as the DBM has been proven to improve the perception of phrases in older adults with hearing loss, especially those who have relatively less threshold in the temporal resolution. DBM helps them to access the available temporal cues by lessening the temporal asynchrony present in older adults. Future studies can investigate the effect of modulation depth in DBM to release masking over speech among older adults with hearing loss in those with a high threshold in GDT that reflects impaired temporal resolution.
Clinical implication of study
The DBM algorithm can be used in hearing aid processing strategy such that higher amplitude of vowels is compressed, and low amplitude of consonants is enhanced. In doing so, the intelligibility to speech improves; consonants are perceived to older adults who have often hearing loss at high frequencies and reduce an upward of masking. In future studies, we may have to train poor performers with this strategy, and over time, we may expect the benefit from them.
Acknowledgments
The author thanks the Institute Director of Speech and Hearing for permitting to conduct the study.
Disclosure
The author reports no conflicts of interest in this work. - No conflicts of interest
Source of Funding - No source of funding.
References
- Phatak S, Allen J (2007) Consonant and vowel confusions in speech-weighted noise. J Acoust Soc Am 121: 2312-2326.
- Humes LE, Coughlin M (2009) Aided speech-identification performance in single-talker competition by older adults with impaired hearing. Scand J Psychol 50: 485-494.
- Strouse A, Ashmead DH, Ohde RN, Grantham WD (1998) Temporal processing in the aging auditory system. J Acoust Soc Am 104: 2385-2399.
- Plomp R (1985) Relations between psychophysical data and speech perception for hearing-impaired subjects. II. J Acoust Soc Am 78: 1261-1270.
- De Filippo CL, Snell KB (1986) Detection of a temporal gap in low-frequency narrow-band signals by normal-hearing and hearing-impaired listeners. J Acoust Soc Am 80: 1354-1358.
- Gordon-Salant S, Fitzgibbons PJ (1993) Temporal factors and speech recognition performance in young and elderly listeners. J Speech Hear Res 36: 1276-1285.
- Tyler RS, Wood EJ, Fernandes M (1983) Frequency resolution and discrimination of constant and dynamic tones in normal and hearing?impaired listeners. J Acoust Soc Am 74: 1190-1199.
- Shannon RV, Zeng FG, Kamath V, Wygonski J, Ekelid M (1995) Speech recognition with primarily temporal cues. Science 270: 303-304.
- Bacon SP, Opie JM, Montoya DY (1998) The effects of hearing loss and noise masking on the masking release for speech in temporally complex backgrounds. J Speech, Lang Hear Res 41: 549-563.
- Freyman RL, Nerbonne GP (1996) Consonant confusions in amplitude-expanded speech. J Speech, Lang Hear Res 39: 1124-1137.
- Lorenzi C, Berthommier F, Apoux F, Bacri N (1999) Effects of envelope expansion on speech recognition. Hear Res 136: 131-138.
- Apoux F, Tribut N, Debruille X, Lorenzi C (2004) Identification of envelope-expanded sentences in normal-hearing and hearing-impaired listeners. Hear Res 189: 13-24.
- Nagarajan SS, Wang X, Merzenich MM, Schreiner CE, Johnston P, et al. (1998) Speech modifications algorithms used for training language learning- impaired children. IEEE Trans Rehabil Eng 6: 257-268.
- Langhans T, Strube HW (1982) Speech enhancement by nonlinear multiband envelope filtering. ICASSP 156-159.
- Shetty HN, Mendhakar A (2015) Deep band modulation and noise effects: Perception of phrases in adults. Hear Balanc Commun 13: 111-117.
- Shetty HN, Kooknoor V (2016) Recognition of deep band modulated consonants in quiet and noise in older individuals with and without hearing loss. J Int Adv Otol 12: 282-289.
- Reisberg B, Ferris SH, de Leon MJ, Crook T (1982) The Global Deterioration Scale for assessment of primary degenerative dementia. Am J Psychiatry 139: 1136-1139.
- Phillips SL, Gordon-Salant S, Fitzgibbons PJ, Yeni-Komshian G (2000) Frequency and Temporal Resolution in Elderly Listeners with Good and Poor Word Recognition. J Speech, Lang Hear Res 43: 217-228.
- Wingfield A, McCoy SL, Peelle JE, Tun PA, Cox LC (2006) Effects of adult aging and hearing loss on comprehension of rapid speech varying in syntactic complexity. J Am Acad Audiol 17: 487-497.
- Weihing JA, Musiek FE, Shinn JB (2007) The effect of presentation level on the Gaps-In-Noise (GIN) test. J Am Acad Audiol 18: 141-150.
- Levitt H (1971) Transformed Up?Down Methods in Psychoacoustics. J Acoust Soc Am 49: 467-477.
- Shetty H, Mendhakar A (2015) Development of phrase recognition test in Kannada language. J Indian Speech Lang Hear Assoc 29: 21.
- Narne VK, Vanaja CS (2008) Effect of Envelope Enhancement on Speech Perception in Individuals with Auditory Neuropathy. Ear Hear 29: 45-53.
- Versfeld NJ, Daalder L, Festen JM, Houtgast T (2000) Method for the selection of sentence materials for efficient measurement of the speech reception threshold. J Acoust Soc Am 107: 1671-1684.
- Lowery KJ, Plyler PN (2013) The effects of noise reduction technologies on the acceptance of background noise. J Am Acad Audiol 24: 649-659.
- Schneider BA, Pichora-Fuller MK (2001) Age-related changes in temporal processing: Implications for speech perception. Semin Hear 22: 227-238.
- Hall JW, Grose JH (1991) Notched-noise measures of frequency selectivity in adults and children using fixed-masker-level and fixed-signal-level presentation. J Speech Hear Res 34: 651-660.
- Carlyon RP, Buus S, Florentine M (1989) Comodulation masking release for three types of modulator as a function of modulation rate. Hear Res 42: 37-45.
- Schlittenlacher J, Moore BCJ (2016) Discrimination of amplitude-modulation depth by subjects with normal and impaired hearing. J Acoust Soc Am 140: 3487-3495.
Citation: Shetty HN, Raju S (2021) Perception of Deep Band Modulated Speech in the Presence of Noise by Elderly Individuals with Hearing Impairment. J Otolaryng Head Neck Surg 7: 61
Copyright: © 2021 Hemanth Narayan Shetty, et al. This is an open-access article distributed under the terms of the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original author and source are credited.